Runge–Kutta methods
In numerical analysis, the Runge–Kutta methods (German pronunciation: [ˌʁʊŋəˈkʊta]) are an important family of implicit and explicit iterative methods for the approximation of solutions of ordinary differential equations. These techniques were developed around 1900 by the German mathematicians C. Runge and M.W. Kutta.
See the article on numerical ordinary differential equations for more background and other methods. See also List of Runge–Kutta methods.
Contents |
Common fourth-order Runge–Kutta method
One member of the family of Runge–Kutta methods is so commonly used that it is often referred to as "RK4", "classical Runge-Kutta method" or simply as "the Runge–Kutta method".
Let an initial value problem be specified as follows.
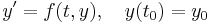
In words, what this means is that the rate at which y changes is a function of y and of t (time). At the start, time is 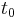 and y is
and y is 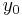 .
.
The RK4 method for this problem is given by the following equations:
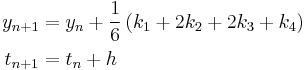
where 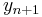 is the RK4 approximation of
is the RK4 approximation of 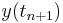 , and
, and
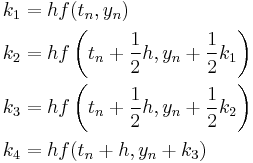
Thus, the next value () is determined by the present value (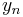 ) plus the weighted average of 4 deltas, where each delta is the product of the size of the interval (
) plus the weighted average of 4 deltas, where each delta is the product of the size of the interval (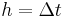 ) and an estimated slope:
) and an estimated slope: 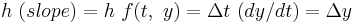 .
.
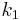 is the delta based on the slope at the beginning of the interval, using , ( Euler's method ) ;
is the delta based on the slope at the beginning of the interval, using , ( Euler's method ) ; is the delta based on the slope at the midpoint of the interval, using
is the delta based on the slope at the midpoint of the interval, using 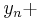 1/2 ;
1/2 ;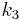 is again the delta based on the slope at the midpoint, but now using 1/2 ;
is again the delta based on the slope at the midpoint, but now using 1/2 ;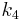 is the delta based on the slope at the end of the interval, using
is the delta based on the slope at the end of the interval, using 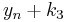 .
.
In averaging the four deltas, greater weight is given to the deltas at the midpoint:
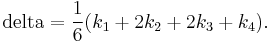
The RK4 method is a fourth-order method, meaning that the error per step is on the order of 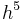 , while the total accumulated error has order
, while the total accumulated error has order 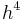 .
.
Note that the above formulae are valid for both scalar- and vector-valued functions (i.e., 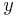 can be a vector and
can be a vector and 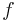 an operator). For example one can integrate the time independent Schrödinger equation using the Hamiltonian operator as function .
an operator). For example one can integrate the time independent Schrödinger equation using the Hamiltonian operator as function .
Also note that if is independent of , so that the differential equation is equivalent to a simple integral, then RK4 is Simpson's rule.
Explicit Runge–Kutta methods
The family of explicit Runge–Kutta methods is a generalization of the RK4 method mentioned above. It is given by
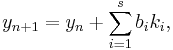
where
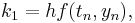
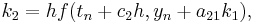
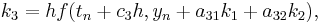
-
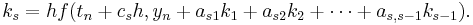
- (Note: the above equations have different but equivalent definitions in different texts).
To specify a particular method, one needs to provide the integer s (the number of stages), and the coefficients aij (for 1 ≤ j < i ≤ s), bi (for i = 1, 2, ..., s) and ci (for i = 2, 3, ..., s). These data are usually arranged in a mnemonic device, known as a Butcher tableau (after John C. Butcher):
| 0 | ||||||
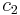 |
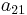 |
|||||
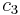 |
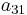 |
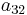 |
||||
 |
|
 |
||||
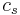 |
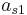 |
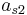 |
 |
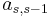 |
||
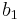 |
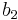 |
|
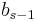 |
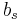 |
The Runge–Kutta method is consistent if
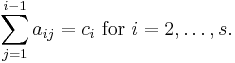
There are also accompanying requirements if we require the method to have a certain order p, meaning that the local truncation error is O(hp+1). These can be derived from the definition of the truncation error itself. For example, a 2-stage method has order 2 if b1 + b2 = 1, b2c2 = 1/2, and b2a21 = 1/2.
Examples
The RK4 method falls in this framework. Its tableau is:
| 0 | |||||
| 1/2 | 1/2 | ||||
| 1/2 | 0 | 1/2 | |||
| 1 | 0 | 0 | 1 | ||
| 1/6 | 1/3 | 1/3 | 1/6 |
However, the simplest Runge–Kutta method is the (forward) Euler method, given by the formula 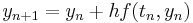 . This is the only consistent explicit Runge–Kutta method with one stage. The corresponding tableau is:
. This is the only consistent explicit Runge–Kutta method with one stage. The corresponding tableau is:
| 0 | ||
| 1 |
An example of a second-order method with two stages is provided by the midpoint method
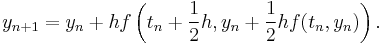
The corresponding tableau is:
| 0 | |||
| 1/2 | 1/2 | ||
| 0 | 1 |
Note that this 'midpoint' method is not the optimal RK2 method. An alternative is provided by Heun's method, where the 1/2's in the tableau above are replaced by 1's and the b's row is [1/2, 1/2].
In fact, a family of RK2 methods is 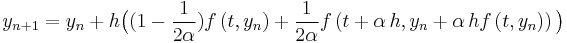 where
where 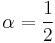 is the mid-point method and
is the mid-point method and 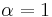 is Heun's method.
is Heun's method.
If one wants to minimize the truncation error, the method below should be used (Atkinson p. 423). Other important methods are Fehlberg, Cash-Karp and Dormand-Prince. To use unequally spaced intervals requires an adaptive stepsize method.
Usage
The following is an example usage of a two-stage explicit Runge–Kutta method:
| 0 | |||
| 2/3 | 2/3 | ||
| 1/4 | 3/4 |
to solve the initial-value problem
![y' = \tan(y)%2B1,\quad y(1)=1,\ t\in [1, 1.1]](/2012-wikipedia_en_all_nopic_01_2012/I/6d396238731f133147ff17c6a24267a7.png)
with step size h=0.025.
The tableau above yields the equivalent corresponding equations below defining the method
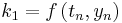
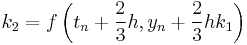
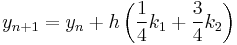
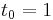 |
|||
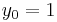 |
|||
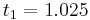 |
|||
|
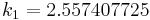 |
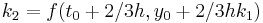 |
|
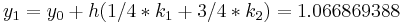 |
|||
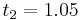 |
|||
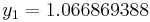 |
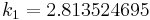 |
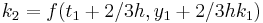 |
|
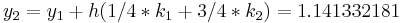 |
|||
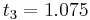 |
|||
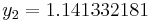 |
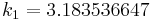 |
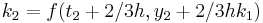 |
|
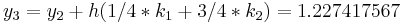 |
|||
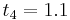 |
|||
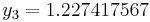 |
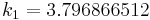 |
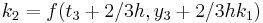 |
|
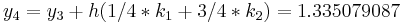 |
|||
The numerical solutions correspond to the underlined values. Note that 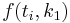 has been calculated to avoid recalculation in the
has been calculated to avoid recalculation in the 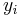 s.
s.
Adaptive Runge–Kutta methods
The adaptive methods are designed to produce an estimate of the local truncation error of a single Runge–Kutta step. This is done by having two methods in the tableau, one with order 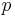 and one with order
and one with order 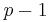 .
.
The lower-order step is given by
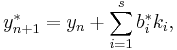
where the 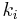 are the same as for the higher order method. Then the error is
are the same as for the higher order method. Then the error is
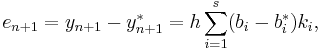
which is 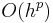 . The Butcher Tableau for this kind of method is extended to give the values of
. The Butcher Tableau for this kind of method is extended to give the values of 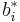 :
:
| 0 | ||||||
|
|
|||||
|
|
|
||||
|
|
|
||||
|
|
|
|
|
||
|
|
|
|
|
||
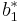 |
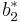 |
|
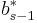 |
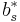 |
The Runge–Kutta–Fehlberg method has two methods of orders 5 and 4. Its extended Butcher Tableau is:
| 0 | |||||||
| 1/4 | 1/4 | ||||||
| 3/8 | 3/32 | 9/32 | |||||
| 12/13 | 1932/2197 | −7200/2197 | 7296/2197 | ||||
| 1 | 439/216 | −8 | 3680/513 | -845/4104 | |||
| 1/2 | −8/27 | 2 | −3544/2565 | 1859/4104 | −11/40 | ||
| 16/135 | 0 | 6656/12825 | 28561/56430 | −9/50 | 2/55 | ||
| 25/216 | 0 | 1408/2565 | 2197/4104 | −1/5 | 0 |
However, the simplest adaptive Runge–Kutta method involves combining the Heun method, which is order 2, with the Euler method, which is order 1. Its extended Butcher Tableau is:
| 0 | |||
| 1 | 1 | ||
| 1/2 | 1/2 | ||
| 1 | 0 |
The error estimate is used to control the stepsize.
Other adaptive Runge–Kutta methods are the Bogacki–Shampine method (orders 3 and 2), the Cash–Karp method and the Dormand–Prince method (both with orders 5 and 4).
Implicit Runge–Kutta methods
The implicit methods are more general than the explicit ones. The distinction shows up in the Butcher Tableau: for an implicit method, the coefficient matrix 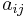 is not necessarily lower triangular:
is not necessarily lower triangular:

The approximate solution to the initial value problem reflects the greater number of coefficients:
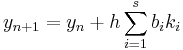
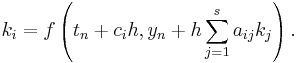
Due to the fullness of the matrix , the evaluation of each is now considerably involved and dependent on the specific function 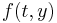 . Despite the difficulties, implicit methods are of great importance due to their high (possibly unconditional) stability, which is especially important in the solution of partial differential equations. The simplest example of an implicit Runge–Kutta method is the backward Euler method:
. Despite the difficulties, implicit methods are of great importance due to their high (possibly unconditional) stability, which is especially important in the solution of partial differential equations. The simplest example of an implicit Runge–Kutta method is the backward Euler method:
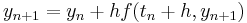
The Butcher Tableau for this is simply:
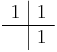
It can be difficult to make sense of even this simple implicit method, as seen from the expression for :
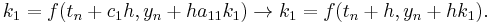
In this case, the awkward expression above can be simplified by noting that
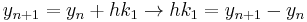
so that
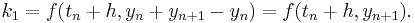
from which
follows. Though simpler than the "raw" representation before manipulation, this is an implicit relation so that the actual solution is problem dependent. Multistep implicit methods have been used with success by some researchers. The combination of stability, higher order accuracy with fewer steps, and stepping that depends only on the previous value makes them attractive; however the complicated problem-specific implementation and the fact that must often be approximated iteratively means that they are not common.
Example
Another example for an implicit Runge-Kutta method is the Crank–Nicolson method, also known as the trapezoid method. Its Butcher Tableau is:
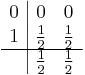
See also
- Euler's Method
- Runge–Kutta method (SDE)
- List of Runge–Kutta methods
- Numerical ordinary differential equations
- Dynamic errors of numerical methods of ODE discretization
References
- John C. Butcher (2003). Numerical methods for ordinary differential equations. John Wiley & Sons. ISBN 0471967580.
- George E. Forsythe, Michael A. Malcolm, and Cleve B. Moler (1977). Computer Methods for Mathematical Computations. Prentice-Hall. (see Chapter 6).
- Ernst Hairer, Syvert Paul Nørsett, and Gerhard Wanner (1993). Solving ordinary differential equations I: Nonstiff problems (2nd ed.). Springer Verlag. ISBN 3-540-56670-8.
- Press, WH; Teukolsky, SA; Vetterling, WT; Flannery, BP (2007). "Section 17.1 Runge-Kutta Method". Numerical Recipes: The Art of Scientific Computing (3rd ed.). New York: Cambridge University Press. ISBN 978-0-521-88068-8. http://apps.nrbook.com/empanel/index.html#pg=907.. Also, Section 17.2. Adaptive Stepsize Control for Runge-Kutta.
- Autar Kaw, Egwu Kalu (2008). Numerical Methods with Applications (1st ed.). autarkaw.com. http://numericalmethods.eng.usf.edu/topics/textbook_index.html.
- Kendall E. Atkinson (1989). An Introduction to Numerical Analysis. John Wiley & Sons.
- F. Cellier, E. Kofman (2006). Continuous System Simulation. Springer Verlag. ISBN 0-387-26102-8.
External links
- Runge–Kutta 4th Order Method
- Runge Kutta Method for O.D.E.'s
- DotNumerics: Ordinary Differential Equations for C# and VB.NET – Initial-value problem for nonstiff and stiff ordinary differential equations (explicit Runge-Kutta, implicit Runge-Kutta, Gear's BDF and Adams-Moulton).
- GafferOnGames – A physics resource for computer programmers
- PottersWheel – Parameter calibration in ODE systems using implicit Runge-Kutta integration
|
|||||||||||